![Featured image of post [Intelligence Artificielle] - Construction d'un ChatGPT hébergé en local](/IA.png)
Syllabus
J’ai essayé de rendre ce document le plus accessible possible en évitant les termes trop techniques. Cependant, à certains moments, ce document entrera plus en détail dans l’hébergement d’une intelligence artificielle. À ce moment-là, j’essaierai de fournir des explications afin que tout le monde puisse comprendre cet article.
Introduction
Depuis novembre 2022, l’IA a pris un nouvel essort avec la mise à disposition gratuite du modèle de langage ChatGPT par OpenAI. Cette démocratisation a conduit à une explosion du nombre de modèles disponibles, notamment grâce à des plateformes telles que Hugging Face. En seulement un an, le nombre de ces modèles est passé de 202 865 à 660 531, témoignant de l’engouement pour cette technologie.
Dans ce contexte florissant, des entreprises comme Mistral se sont distinguées en développant des modèles rivalisant avec les géants du secteur tels que ChatGPT et Meta. Cette compétition a ouvert de nouvelles perspectives, comme en atteste le graphique comparatif ci-dessous.
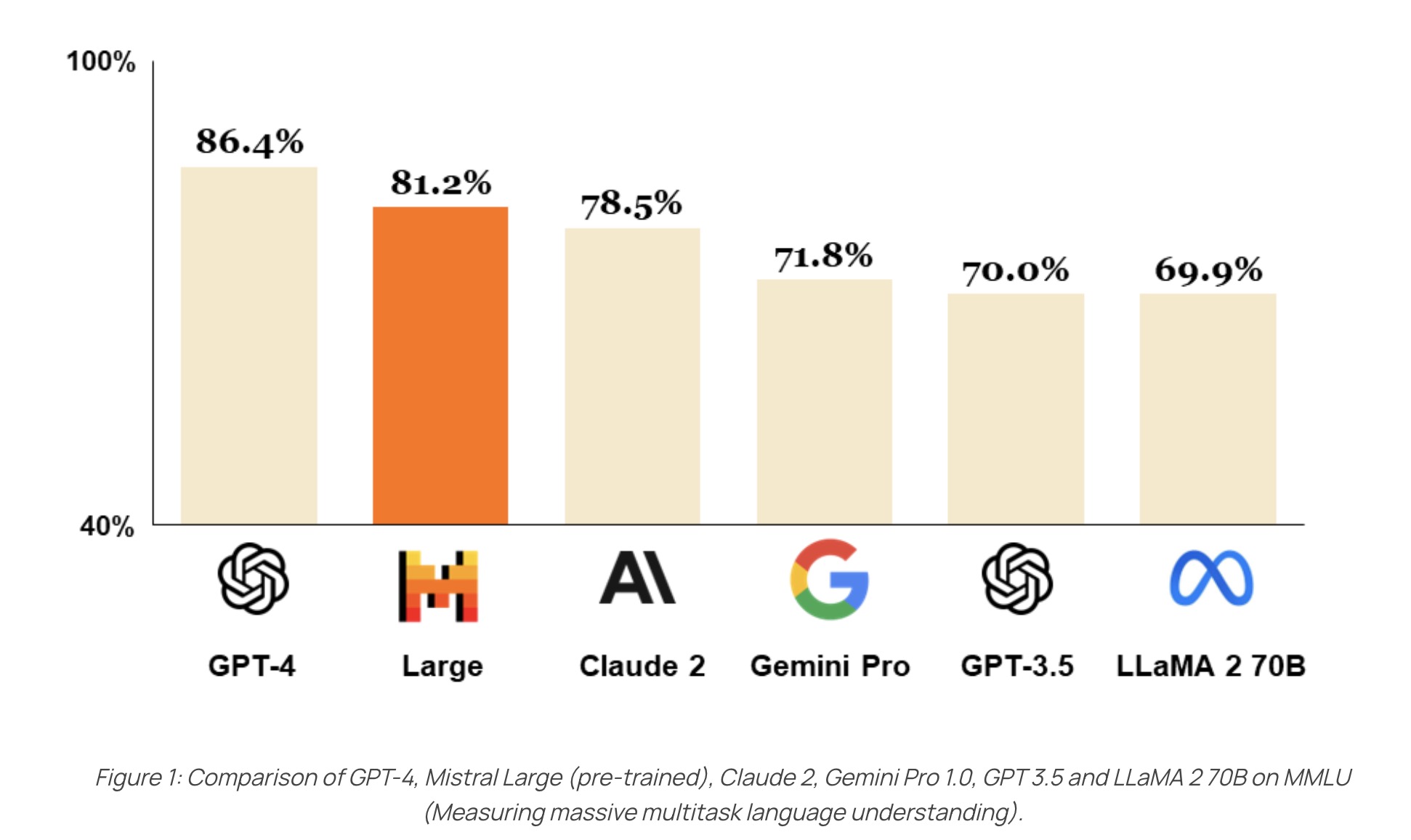
Dans cet article, nous allons explorer la construction d’un modèle de conversation similaire à ChatGPT, mais hébergé localement. Pour ce faire, nous optons pour une approche pratique en utilisant un Raspberry Pi 4B avec 1 Go de RAM et un MacBook Pro M1 avec 16 Go de RAM pour l’hébergement des modèles. Cette démarche, inspirée par une vidéo de NetworkChuck intitulée “Host ALL your AI locally”, s’inscrit dans une tendance croissante à privilégier l’hébergement local des modèles d’IA, offrant ainsi davantage de contrôle et de confidentialité aux utilisateurs. De plus, elle permet l’utilisation de modèles personnalisés, mieux adaptés à des besoins spécifiques et potentiellement plus performants que les modèles génériques disponibles en ligne.
Explication des models utilisés
Dans notre projet de construction d’un ChatGPT local, nous faisons appel à différents Large Language Models (LLM). Ces modèles permettent la génération de texte cohérent et pertinent, similaire à celui de ChatGPT. Ils se distinguent par leur capacité à comprendre et produire du texte de manière intelligente, ce qui est déterminant pour des interactions naturelles avec les utilisateurs.
Les LLM se caractérisent par plusieurs aspects :
Taille : : Il s’agit du nombre de paramètres (tokens) que ces modèles peuvent comprendre. Cependant, il est important de noter que la qualité d’un modèle ne se limite pas à sa taille seule. La taille du modèle peut avoir un impact sur la performance du ChatGPT local, influençant à la fois la rapidité de réponse et la qualité des réponses générées.
Capacité de compréhension : Les LLM sont capables de faire des déductions basées sur le texte donné, ce qui leur permet de comprendre la signification du contenu au-delà des mots eux-mêmes. Cette capacité est essentielle pour générer des réponses pertinentes et adaptées à divers scénarios d’utilisation.
Technique d’apprentissage : Les LLM utilisent des techniques telles que le traitement en parallèle des mots et le fine-tuning pour améliorer leur compréhension du texte et leur performance dans des domaines spécifiques. Cette évolutivité leur permet de s’adapter aux besoins spécifiques de l’utilisateur ou du domaine d’application.
Dans le cadre de notre “projet”, nous avons sélectionné plusieurs modèles pour leurs performances et leurs spécificités :
Mistral 7B Mistral Model: Ce modèle de Mistral comprend 7 milliards de tokens. Le plus petit model de Mistral mais le seul pouvant être exécuté par mon Mac.
Llama-3 8B Lama Model: Dernier model de Meta, ce modèle rivalise avec ChatGPT-4.
Dolphin-2.9.1-llama-3-8b Dolphin Llama: Un autre modèle de Meta, moins restrictif que d’autres, offrant une grande flexibilité dans la génération de texte. Il peut être adapté et fine-tuné pour répondre aux besoins spécifiques de l’utilisateur, offrant ainsi une solution personnalisée pour des scénarios d’utilisation variés.
Le modèle Dolphin se distingue par sa flexibilité et sa capacité à s’adapter à une large gamme de tâches. Contrairement à certains autres modèles qui peuvent avoir des restrictions sur les sujets ou les types de questions qu’ils peuvent traiter, le modèle Dolphin est conçu pour être plus ouvert, permettant aux utilisateurs de poser des questions sans contraintes. Cette caractéristique en fait un choix idéal permettant de converser avec notre ChatGPT sans avoir à nous soucier des restrictions.
Installation des models
Après avoir défini les modèles utilisés, nous allons maintenant définir l’architecture de notre projet.
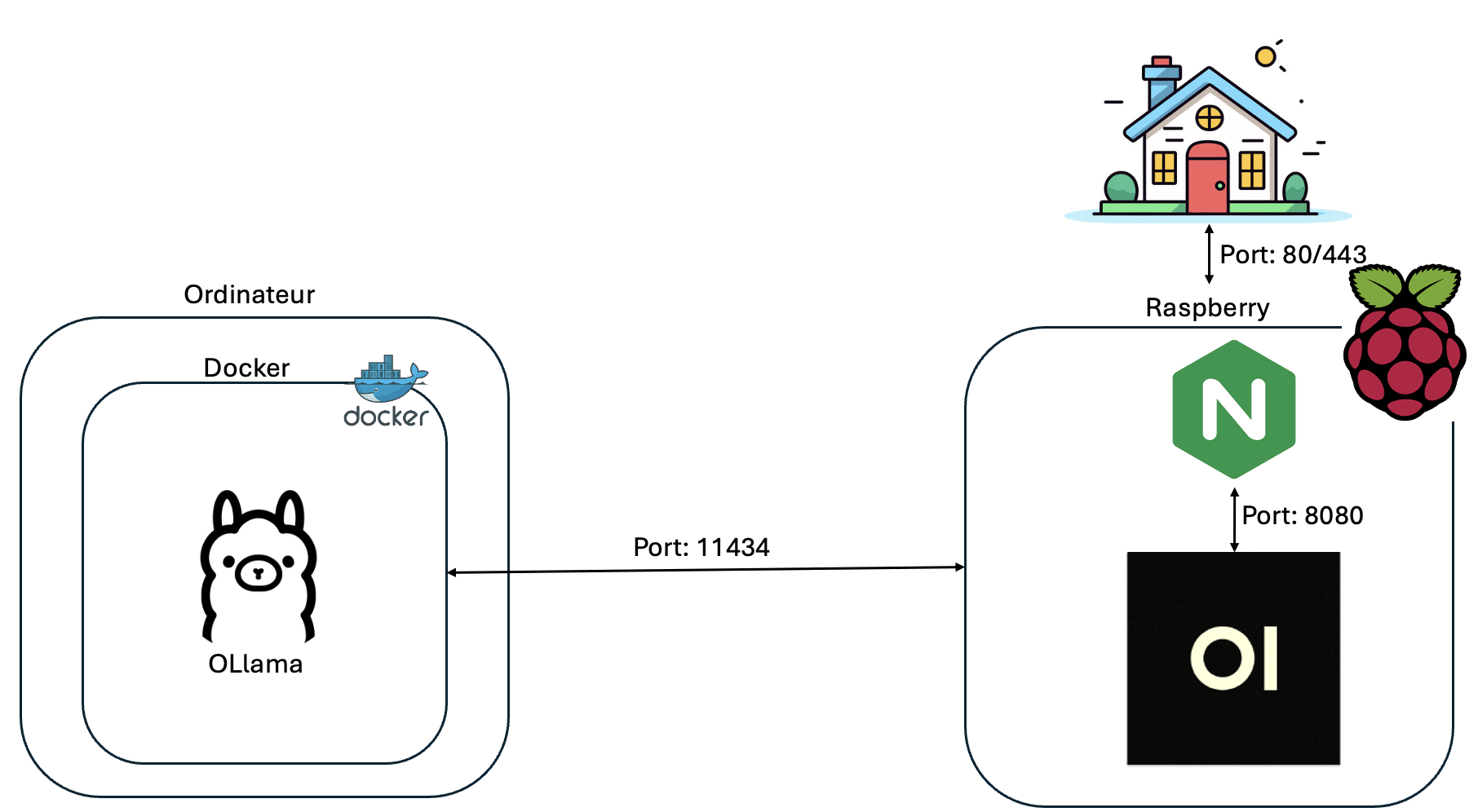
Après avoir défini les modèles utilisés, nous devons installer Ollama, un framework permettant d’exécuter des LLM en local. J’ai voulu installer Ollama dans un conteneur Docker. Pour cela, j’utilise Docker Desktop car je suis sur Mac, mais vous pouvez très facilement utiliser Docker. (Installation: https://docs.docker.com/engine/install/debian/).
Après l’installation de Docker, nous devons installer l’image Docker. Pour cela, n’ayant pas de GPU Nvidia, j’ai lancé l’image grâce à la commande suivante :
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Cependant, si vous avez une carte Nvidia, vous pouvez utiliser cette commande afin d’utiliser votre GPU :
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
Ensuite, nous devons exécuter les 3 modèles ci-dessus. Pour cela, nous devons utiliser les commandes suivantes :
docker exec -it ollama ollama run llama3
docker exec -it ollama ollama run mistral
docker exec -it ollama ollama run dolphin-llama3:8b-256k
Après avoir effectué toutes ces étapes, vous devriez normalement avoir accès à Ollama en local. Pour vous assurer que tout fonctionne correctement, vérifiez si vous obtenez une réponse lorsque vous accédez à l’URL : http://:11434. Si vous obtenez comme réponse Ollama is running, cela signifie que Ollama a bien démarré correctement.
Installation de l’interface graphique
Pour faciliter l’interaction avec Ollama, nous allons installer OpenWebUI, une interface graphique. OpenWebUI permettra de gérer et de contrôler les modèles de manière simple, directement depuis notre browser. Pour ce faire, nous allons suivre ces étapes:
Étape 1 : Installation de OpenWebUI
Nous avons commencé par installer OpenWebUI sur notre Raspberry Pi, qui doit bien sûr être connecté au même réseau que l’instance Ollama. Après avoir préalablement installé Docker sur le Raspberry, nous avons lancé l’image OpenWebUI en utilisant la commande suivante :
sudo docker run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://<server-ip>:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main
Étape 2 : Configuration du reverse proxy
Une fois que nous avons connecté Ollama à une interface graphique, notre prochaine étape a été de permettre l’accès à cette interface web depuis n’importe quel appareil de notre réseau. Pour cela, nous avons utilisé Nginx en tant que reverse proxy. Nous avons commencé par installer Nginx en exécutant la commande suivante :
Ensuite, nous avons modifié la configuration de Nginx comme expliqué ci-dessous :
server {
listen 80;
server_name 192.168.0.190;
location / {
proxy_pass http://127.0.0.1:8080;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Enfin, pour appliquer cette configuration, nous avons redémarré le service Nginx en exécutant la commande suivante : sudo systemctl restart nginx
Configuration de OpenWebUI
Une fois que le reverse proxy est configuré, nous pouvons à accéder à la plateforme OpenWebUI. Pour cela, il suffit de se rendre à l’URL suivante : http://. À ce stade, vous serez invités à vous connecter. Le premier compte que vous créerez sera automatiquement attribué le rôle d’administrateur.
Une fois connecté, vous serez accueilli par l’interface d’OpenWebUI, comme illustré ci-dessous :
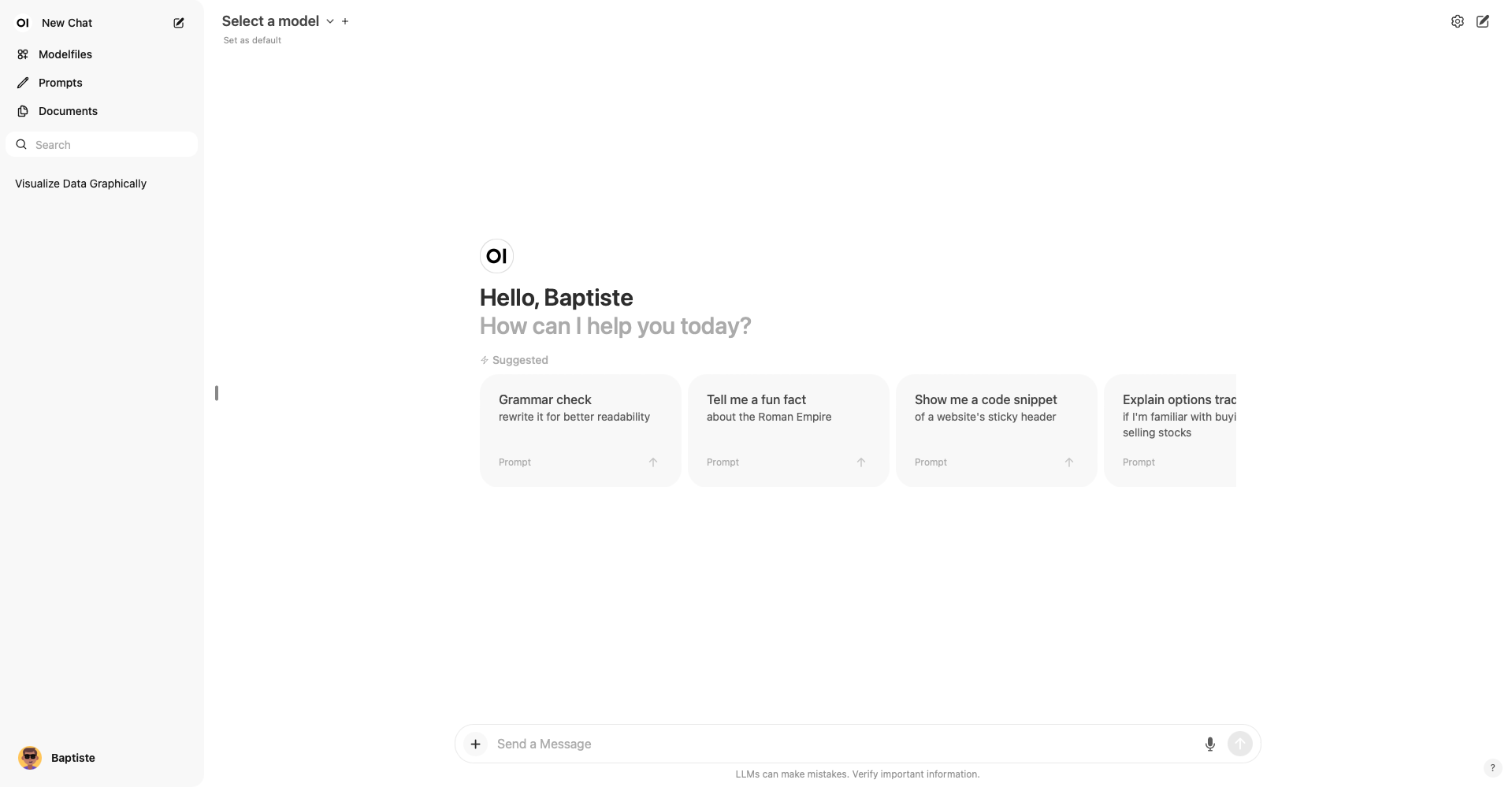
Dès lors, vous pourrez accéder à différentes sections et configurer votre instance selon vos besoins spécifiques. Voici quelques fonctionnalités principales que vous pouvez explorer :
- Section “Modelfiles” : Cette section nous permet de personnaliser les réponses générées par notre instance en fonction de nos préférences. Par exemple, nous pouvons spécifier des domaines spécifiques tels que “Programming” et “Education” pour améliorer la pertinence des réponses dans ces domaines. Cette personnalisation permet d’enrichir le contexte du modèle et d’obtenir des réponses plus précises et adaptées.
Section “Documents” : Nous avons la possibilité de fournir des fichiers texte aux Large Language Models (LLMs) utilisés par notre instance. Ces documents serviront de source d’information supplémentaire pour les modèles, les aidant à mieux comprendre les sujets abordés et à améliorer la qualité de leurs réponses.
Attribution de tags aux prompts : Chaque prompt peut être associé à un ou plusieurs tags, ce qui facilite leur classification et leur recherche ultérieure. Cette fonctionnalité nous permet d’organiser efficacement nos prompts et de retrouver rapidement ceux qui nous intéressent.
De plus, la fonction de recherche intégrée simplifie considérablement la recherche des anciens prompts.
Utilisation de différents models
Dans cette dernière partie, nous plongeons dans les différences concrètes entre les différents modèles. Il devient évident dès les premières interactions que les modèles Llama et Mistral produisent des réponses presque indiscernables. Cependant, le modèle Dolphin se distingue de manière remarquable. Sa caractéristique la plus notable réside dans sa capacité à répondre à une gamme diversifiée de questions, sans aucune restriction apparente. Par exemple, j’ai récemment sollicité une explication détaillée accompagnée d’exemples sur le concept complexe des injections SQL, un sujet que ChatGPT aurait très probablement esquivé. Cette flexibilité offre une ouverture sans précédent pour explorer des sujets spécifiques et variés. Ainsi, l’implémentation de ces modèles en local, en complément de ChatGPT, se révèle être une solution particulièrement judicieuse pour des conversations détaillées et approfondies sur des sujets complexes.
Conclusion
Malgré la légère différence de vitesse dans la génération des réponses par mes LLMs locaux par rapport à ChatGPT, conserver mes données en local demeure un avantage majeur, à mes yeux. De plus, la flexibilité offerte par la possibilité d’utiliser le modèle de notre choix est d’une importance capitale. En effet, grâce au modèle Dolphin, nous avons la liberté de poser une vaste gamme de questions sans aucune limitation, une caractéristique particulièrement bénéfique dans le domaine de la cybersécurité. Cette capacité d’adaptation constitue un atout considérable, renforçant ainsi l’efficacité de mes interactions avec les LLMs en local.